

A new publication in the Journal of Dental Research by MetaHealth researchers from WP2 calls for a new way of thinking about oral health promotion. Current oral health promotion mainly focuses on encouraging individuals to brush their teeth, eat less sugar and visit the dentist regularly. While these actions are important, they address only part of theproblem. Oral health is also influenced by many interconnected factors, including healthcare systems, public policy, the food environment and social inequalities.
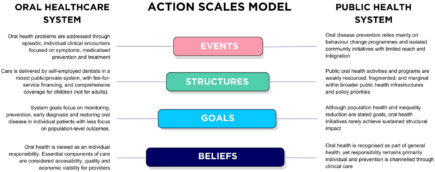
In the paper, the authors use the Action Scales Model, a systems thinking framework that helps identify where meaningful change can be achieved. The model illustrates thatimproving oral health is about more than clinical care. It also requires changes in how healthcare is organised, what the health system prioritises, and the beliefs and values thatguide policies and professional practice. The authors argue that sustainable improvements in oral health require action beyond the dental setting, including stronger prevention policies, better integration of oral health into broader public health strategies, and system-level changes in how healthcare is organised, how prevention is funded, and howsocial and policy environments influence health behaviours and outcomes.
This publication fits closely with the aims of MetaHealth Work Package 5, which focuses on designing and implementing multi-level interventions to promote healthier lifestyles and prevent dental caries and childhood overweight during the first 1,000 days of life. A systems approach can help identify opportunities for preventing both dental caries andchildhood overweight by addressing shared determinants and creating lasting improvements in health.
Read the full article in the Journal of Dental Research
Background: Many unhealthy habits develop in early childhood and can lead to long-term health risks, which disproportionately affect children with low socioeconomic position (SEP). Digital and blended lifestyle interventions can promote healthier lifestyles, yet families with lower SEP remain underrepresented and face unique barriers to healthy behaviors and intervention access. As a result, it remains unclear which intervention characteristics are most effective for these populations.
Objective: This study by Lea Hohendorf and colleagues from WP6 aimed to identify and map digital and blended lifestyle interventions targeting preschool-aged children and explore how intervention characteristics and reported effectiveness patterns differ between interventions for the general population and low SEP families.
Methods: A search across Scopus, Web of Science, Cochrane Library, ERIC, and ACM Digital Library was conducted. Studies were eligible if they (1) targeted preschool-aged children (6 months to 5 years) or caregivers, (2) evaluated a digital or blended lifestyle intervention, and (3) addressed at least one behavioral domain (nutrition, physical activity, sedentary behavior, sleep, and oral health). Studies focusing on pregnant women, children aged >5 years, or interventions delivered solely nondigitally were excluded. Screening and prioritization were supported by artificial intelligence–assisted software (ASReview; Utrecht University). Data covered intervention targets, populations, theoretical and guideline foundations, delivery modes and settings, and persuasive systems design features. Intervention characteristics and effectiveness categories were synthesized descriptively. The methodological quality of quasi-experimental studies was assessed using the Joanna Briggs Institute critical appraisal tools.
Results: A total of 77 studies describing 54 interventions were included. Of these, 35 targeted the general population, and 19 focused solely on low SEP families. Interventions were similar across groups: typically parent-focused, targeting multiple lifestyle domains, and informed by theories, frameworks, or evidence-based guidelines. Low SEP interventions more often used text messaging, included fewer persuasive design features, and tended toward single delivery channels. Effectiveness findings were mixed; no consistent patterns emerged when interventions were grouped by their characteristics. Among low SEP interventions only, less effective interventions more often targeted multiple behaviors and included more persuasive systems design features.
Conclusions: To our knowledge, this is one of the first reviews to map digital and blended lifestyle interventions for preschool-aged children while comparing intervention characteristics and descriptive effectiveness patterns across general and low SEP populations. The review highlights heterogeneity in intervention characteristics and outcomes and identifies gaps where evidence is limited. These findings underscore the need to better represent low SEP families in intervention research, strengthen understanding of feasibility and contextual fit, and support multilevel approaches that reflect families’ everyday contexts. However, the findings should be interpreted in light of several limitations, including the exclusion of gray literature, partial double-screening, the possibility that artificial intelligence–assisted prioritization may have omitted relevant studies, and variation in the reporting of intervention components across studies.

Source: DALL-E (AI-generated image); Copyright: Public Domain; License: Public Domain (CC0)
Read more
Nicholas Pucci and other researchers from WP2 (we) investigated how infant oral bacterial communities develop during their first six months of life, with the aim to understand which microbes colonize, how they establish themselves and why they succeed together. Using high throughput DNA sequencing techniques, we analyzed oral samples from 24 mother-infant pairs at one and six months after birth. We found two abundant, but previously unknown bacterial species (one Streptococcus spp. and one Rothia spp.) at six months of age. These bacteria consistently appear together across different babies, suggesting they may depend on each other for survival and growth.
By reconstructing the genomes of these bacteria directly from our samples, we discovered specific genetic features that help explain their success in the infant mouth. Streptococcus carries genes involved in amino acid biosynthesis (including arginine biosynthesis using amino acids present in breast milk) as well as enzymes that help break down carbohydrates in the oral biofilm. Rothia has genes associated with cell membrane biosynthesis and carbohydrate metabolism, while producing nutrients that Streptococcus needs. We predict these bacteria exchange key nutrients like ornithine and lysine, creating a mutually beneficial partnership.
Overall, our findings offer a first look at the functional roles and potential interactions of these overlooked species, laying the groundwork for future experimental work to validate these predictions.
Read more
In a study published in the International Journal of Data Science and Analytics, researchers Roman van Eldijk, Shivam Kumar, and Vivek Sheraton M from WP3 introduce a visualization module for FAIRDatabase, an open-source platform designed to handle protected biological data. The tool addresses a critical bottleneck in modern science: the sheer volume of microbiome data is exploding, but legal constraints and security risks often force scientists to spend months navigating contracts and downloading files before they can even begin their analysis.
“Think of it like a high-security vault where you can examine the contents and run complex experiments, but the data itself never actually leaves the building,” explains the team. This is achieved through edge computing where computations run in secure cloud environments (using Supabase edge functions) rather than on a researcher’s local computer. Sensitive genetic information remains encrypted and in place, eliminating the risk of leaks or theft while still allowing for sophisticated analysis. The innovation isn’t just about security; it’s about making that security seamless without compromising on analytical power or mathematical rigor. For the end user, the scientist, the experience is designed to be immediate and intuitive. The module generates interactive heatmaps and scatter plots (known as PCoA plots) that map bacterial communities in visual space. Researchers can color-code data points by patient metadata, such as age, diet, or disease status, using palettes specifically chosen for colorblind accessibility.
While the tool is tailored for microbiome research, its implications stretch far beyond gut bacteria. It serves as a proof-of-concept for privacy-preserving visualization in any field handling sensitive data, from human genomics to patient health records. By demonstrating that complex, composition-aware analysis can coexist with ironclad security, the researchers have laid the groundwork for a future where scientific discovery isn’t hamstrung by data silos.
Read more
Underutilization of oral healthcare can exacerbate health disparities by allowing preventable oral health problems to go untreated. This scoping review provides an overview of underutilization of oral healthcare, aiming to provide insight into populations at risk for underutilization and which individual and systemic barriers contribute.
Searches were conducted in PubMed and Embase, focusing on studies published between 2018–2025 in high-income countries and populations aged 0–65 years. Studies addressing underutilization of oral healthcare were considered for inclusion.
Seventy-nine studies were included. Populations at risk for underutilization included individuals with chronic illnesses, rural residents, migrants, children, pregnant women and ethnic minorities. Individual barriers included financial constraints, low health literacy, dental anxiety, and competing health priorities, while systemic barriers to utilization of oral healthcare involved high treatment costs, lack of insurance, limited provider availability, and discrimination. Overarching determinants of underutilization commonly included low income, lack of education, and rural residence.
Underutilization of oral healthcare is rarely driven by a single individual or systemic factor but instead results from a combination of multiple barriers. Financial constraints, low health literacy, and dental anxiety often intersect with systemic challenges such as lack of insurance and provider shortages. Addressing underutilization requires targeted, multi-level interventions that consider both individual and structural determinants to improve access to oral healthcare.
Read more
Researchers from WP2 with partners from Porto University in the lead published in the Journal of Oral Microbiology “Oral-heart axis from pregnancy and postpartum: maternal oral microbiota relates with cardiac reverse remodeling”.
Background: Emerging evidence links the oral microbiota to cardiovascular health, but this relationship remains poorly understood during pregnancy. Here, we investigated associations between the oral microbiota, cardiovascular physiology, and diet during and after pregnancy.
Materials and methods: Salivary microbiota from 65 women in the 3rd trimester and 6 months postpartum were analyzed by 16S rRNA gene sequencing. Cardiovascular function was assessed via echocardiography, endothelial function by EndoPATTM, nitric oxide levels by plasma nitrate/nitrite levels, and diet through the Food Frequency
Questionnaire.
Results: Left ventricular end-diastolic volume (LVEDV) was negatively associated with nitrite-reducing bacteria, namely, Prevotella, at both time points. Cluster analysis identified two reverse-remodeling profiles, one with poorer remodeling, greater postpartum weight retention and higher pregnancy microbial richness enriched with inflammation-associated
genera that persisted postpartum. Higher Porphyromonas abundance during pregnancy predicted smaller postpartum LVEDV reductions. At postpartum, in the healthier cluster, Neisseria correlated with left ventricular mass changes and Parvimonas correlated with ΔLVEDV. Multivariate models confirmed independent microbiota–cardiac associations, while regression analyses did not support a clear diet–microbiota–cardiac axis.
Conclusion: In conclusion, the salivary microbiota profile was associated with cardiovascular physiology during pregnancy and with postpartum cardiovascular recovery.
These findings warrant confirmation in larger cohorts to clarify their clinical relevance.
This study examined the perspectives of policy officials affiliated with Dutch municipalities exploring advertisement restrictions on unhealthy and unsustainable products in public outdoor spaces.
In this qualitative study, Dutch municipal policy officials were interviewed in person or online via semi-structured interviews in autumn 2024. Interviews covered the content of proposed restrictions, the municipality’s policy phase, key stakeholders, barriers, facilitators, and policy goals. Interviews were audio-recorded and transcribed verbatim. Analysis was based on a thematic content analysis.
We interviewed 18 policy officials from 13 Dutch municipalities. They indicated that advertisement restrictions were often initiated by left-wing council members, driven by the combination of a momentum (e.g., commitment to a healthy and green future), a favourable political climate (e.g., demand for restrictions from local political parties), and a policy window (e.g., revising municipality advertisement policies). They indicated that the development, implementation and long-term viability of advertisement restrictions depended on policy consistency (e.g., establishing definitions of products to restrict), managing the risks to policy implementation (e.g., financial losses following reduced advertisement revenue) and practical barriers (e.g., existing tenders). Some policy officials doubted the impact of these restrictions on consumer behaviours, but speculated that their signalling effect could affect public support for similar policies.
Political will, momentum and an opening policy window allowed for the development and sometimes implementation of advertisement restrictions. Future research should explore wider stakeholder support for these policies, how to effectively mitigate perceived risks associated with their implementation, and their long-term impact on consumer behaviours.

Hospitals and healthcare institutes have incredibly valuable patient and research participant data that could drive major medical breakthroughs. But, it’s private and sensitive that sharing it safely is a huge challenge under strict privacy laws. To solve this, researchers from MetaHealth explored Federated Learning (FL), a method where institutes train computational/AI models on their own private data and only share the learned insights (like updated model instructions) with each other, never the raw patient records.
They have developed a tool called “FedDeepInsight” that transforms complex medical tables into images (since AI is great at analyzing pictures), making the FL process more accurate. Testing showed that adding Differential Privacy (like carefully controlled digital static) ensured no individual patient details could be figured out from the shared information, creating a promising way to unlock medical data’s power while keeping it completely secure and private.
 >
>
The initial colonization of the infant gut is a complex process that defines the foundation for a healthy microbiome development. Bifidobacterium longum is one of the first colonizers of newborns’ gut, playing a crucial role in the healthy development of both the host and its microbiome. However, B. longum exhibits significant genomic diversity, with subspecies (e.g., Bifidobacterium longum subsp. infantis and subsp. longum) displaying distinct ecological and metabolic strategies including differential capabilities to break down human milk glycans (HMGs). To promote healthy infant microbiome development, a good understanding of the factors governing infant microbiome dynamics is required.
We analyzed newly sequenced gut microbiome samples of mother-infant pairs from the Amsterdam Infant Microbiome Study (AIMS) and four publicly available datasets to identify important environmental and bifidobacterial features associated with the colonization success and succession outcomes of B. longum subspecies. Metagenome-assembled genomes (MAGs) were generated and assessed to identify characteristics of B. longum subspecies in relation to early-life gut colonization. We further implemented machine learning tools to identify significant features associated with B. longum subspecies abundance.
B. longum subsp. longum was the most abundant and prevalent gut Bifidobacterium at one month, being replaced by B. longum subsp. infantisat six months of age. By utilizing metagenome-assembled genomes (MAGs), we reveal significant differences between and within B. longumsubspecies in their potential to break down HMGs. We further combined strain-tracking, meta-pangenomics and machine learning to understand these abundance dynamics and found an interplay of priority effects, milk-feeding type and HMG-utilization potential to govern them across the first six months of life. We find higher abundances of B. longum subsp. longumin the maternal gut microbiome, vertical transmission, breast milk and a broader range of HMG-utilizing genes to promote its abundance at one month of age. Eventually, we find B. longum subsp. longum to be replaced by B. longum subsp. infantis at six months of age due to a combination of nutritional intake, HMG-utilization potential and a diminishment of priority effects.
Our results establish a strain-level ecological framework explaining early-life abundance dynamics of B. longum subspecies. We highlight the role of priority effects, nutrition and significant variability in HMG-utilization potential in determining the predictable colonization and succession trajectories of B. longum subspecies, with potential implications for promoting infant health and well-being.
Read more
The human gut harbors native microbial communities, forming a highly complex ecosystem. Synthetic microbial communities (SynComs) of the human gut are an assembly of microorganisms isolated from human mucosa or fecal samples. In recent decades, the ever-expanding culturing capacity and affordable sequencing, together with advanced computational modeling, started a ‘‘golden age’’ for harnessing the beneficial potential of SynComs to fight gastrointestinal disorders, such as infections and chronic inflammatory bowel diseases.
As simplified and completely defined microbiota, SynComs offer a promising reductionist approach to understanding the multispecies and multikingdom interactions in the microbe–host-immune axis. However, there are still many challenges to overcome before we can precisely construct SynComs of designed function and efficacy that allow the translation of scientific findings to patients’ treatments. Here, we discussed the strategies used to design, assemble, and test a SynCom, and address the significant challenges, which are of microbiological, engineering, and translational nature, that stand in the way of using SynComs as live bacterial therapeutics.

The authors have developed tools for creating big, organized library (database) for microbiome data (germs that live in and on our bodies) that can be easily accessed and used by researchers. This will help scientists share information and come up with new ways to tackle health issues, while also following privacy laws and protecting people’s personal information. They use a special platform to build the database and create a helpful set of tools that even non-experts can use to understand and work with the data. Below is a technical summary of the work.
The article proposes the creation of a real-time FAIR (Findable, Accessible, Interoperable, Reusable) compliant database for the handling and storage of human microbiome and host-associated data. This database development pipeline aims to facilitate innovation and reduce costs in research by making standardized, transparent, and readily available (meta)data.
The authors discuss potential conflicts arising from privacy laws and possible human genome sequences in metagenome shotgun data and propose alternate pathways for achieving compliance in such cases. They identify sensitive microbiome data, such as DNA sequences or geolocalized metadata, and consider the role of GDPR data regulations. The database is implemented using an open-source development platform, Supabase, allowing researchers to access, upload, download, and interact with human microbiome data in a FAIR compliant manner. Additionally, a large language model (LLM) is deployed to enable knowledge dissemination and non-expert usage of the database.
Read more