

General aim
To develop and validate mathematical models to numerically simulate the interplay between microbiome, lifestyle, culture and environment and their effects on oral and metabolic health during the first 1000 days of life.
Objectives at micro level
To model the dynamics and species competition within the microbiome communities (gut and oral) using inputs from in-vivo (WP2) and in-vitro studies (WP4) at functional and taxonomic levels.
Objectives at meso level
To model the interplay between host and microbiome in both directions: how does the microbiome influence the host’s health and vice versa.
Objectives at macro level
To model the links between various macro level parameters (lifestyle, dietary habits, demographics, sociocultural factors) and the models in the micro level.
Active period
Year 3-8
UvA-SILS, UvA-IBED, AUMC, TNO Microbiology & Systems Biology, TNO Child Health.


BaseClear, NIBI, Onkolyze, Supabase, Bètapartners.
All PhD students and post-doc in Work Package 3 (WP3) have now commenced their research. The regular group meeting of WP3 are being held to foster collaborative efforts within the work package. Over the past months, WP3 has overseen the completion of two Master’s theses and three Bachelor’s theses.
Research output:
Allan Duah’s Master’s thesis has led to a paper titled “FedDeepInsight - A privacy-first federated learning architecture for medical data” which has been published in the Informatics in Medicine Unlocked journal.
Shivam Kumar (PhD student) and Xiaoqing Han (Masters Student) are currently working on a research article titled “Agent-Based Modeling of Microbial and Metabolite Interactions in Early Oral Biofilms” which is currently in the final phases of preparation.
Master students Zefan Zhu and Matthias Louws have co-authored a manuscript titled “FAIR and Square: Implementing User-Centric Interfaces for a Secure and Compliant Healthcare Database,” which is being submitted to Information Systems Frontiers journal. It is also available via preprint: https://doi.org/10.21203/rs.3.rs-8205252/v1
A paper on edge-based microbiome visualizations, “Integrating Microbiome Data Visualization into FAIRDatabase using Edge Functions”, by van Eldijk, S Kumar and MV Sheraton has been published in the International Journal of Data Science and Analytics,.
A research article by Tu-Ky Ly titled “A PBK–Bayesian Network Framework for Gut Microbiome–Host Metabolic Modelling during the First 1000 Days of Life” has been accepted for the ISCS 2026 conference and will be published in Lecture Notes in Computer Science.
Infrastructure development:
A server required for handling data from metagenomics analysis is currently tested within the University of Amsterdam (UvA) infrastructure. Additionally, automated translations of field identifiers from metadata have been carried out in parallel to streamline data processing and analysis.
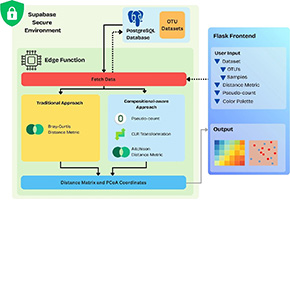
In a study published in the International Journal of Data Science and Analytics, researchers Roman van Eldijk, Shivam Kumar, and Vivek Sheraton M from WP3 introduce a visualization module for FAIRDatabase, an open-source platform designed to handle protected biological data. The tool addresses a critical bottleneck in modern science: the sheer volume of microbiome data is exploding, but legal constraints and security risks often force scientists to spend months navigating contracts and downloading files before they can even begin their analysis.
“Think of it like a high-security vault where you can examine the contents and run complex experiments, but the data itself never actually leaves the building,” explains the team. This is achieved through edge computing where computations run in secure cloud environments (using Supabase edge functions) rather than on a researcher’s local computer. Sensitive genetic information remains encrypted and in place, eliminating the risk of leaks or theft while still allowing for sophisticated analysis. The innovation isn’t just about security; it’s about making that security seamless without compromising on analytical power or mathematical rigor. For the end user, the scientist, the experience is designed to be immediate and intuitive. The module generates interactive heatmaps and scatter plots (known as PCoA plots) that map bacterial communities in visual space. Researchers can color-code data points by patient metadata, such as age, diet, or disease status, using palettes specifically chosen for colorblind accessibility.
While the tool is tailored for microbiome research, its implications stretch far beyond gut bacteria. It serves as a proof-of-concept for privacy-preserving visualization in any field handling sensitive data, from human genomics to patient health records. By demonstrating that complex, composition-aware analysis can coexist with ironclad security, the researchers have laid the groundwork for a future where scientific discovery isn’t hamstrung by data silos.
Read more
Hospitals and healthcare institutes have incredibly valuable patient and research participant data that could drive major medical breakthroughs. But, it’s private and sensitive that sharing it safely is a huge challenge under strict privacy laws. To solve this, researchers from MetaHealth explored Federated Learning (FL), a method where institutes train computational/AI models on their own private data and only share the learned insights (like updated model instructions) with each other, never the raw patient records.
They have developed a tool called “FedDeepInsight” that transforms complex medical tables into images (since AI is great at analyzing pictures), making the FL process more accurate. Testing showed that adding Differential Privacy (like carefully controlled digital static) ensured no individual patient details could be figured out from the shared information, creating a promising way to unlock medical data’s power while keeping it completely secure and private.
 >
>

The authors have developed tools for creating big, organized library (database) for microbiome data (germs that live in and on our bodies) that can be easily accessed and used by researchers. This will help scientists share information and come up with new ways to tackle health issues, while also following privacy laws and protecting people’s personal information. They use a special platform to build the database and create a helpful set of tools that even non-experts can use to understand and work with the data. Below is a technical summary of the work.
The article proposes the creation of a real-time FAIR (Findable, Accessible, Interoperable, Reusable) compliant database for the handling and storage of human microbiome and host-associated data. This database development pipeline aims to facilitate innovation and reduce costs in research by making standardized, transparent, and readily available (meta)data.
The authors discuss potential conflicts arising from privacy laws and possible human genome sequences in metagenome shotgun data and propose alternate pathways for achieving compliance in such cases. They identify sensitive microbiome data, such as DNA sequences or geolocalized metadata, and consider the role of GDPR data regulations. The database is implemented using an open-source development platform, Supabase, allowing researchers to access, upload, download, and interact with human microbiome data in a FAIR compliant manner. Additionally, a large language model (LLM) is deployed to enable knowledge dissemination and non-expert usage of the database.
Read more

