

Algemeen doel
Het ontwikkelen en valideren van wiskundige modellen om de wisselwerking tussen microbioom, leefstijl, cultuur en omgeving en hun effecten op de mondgezondheid en metabole gezondheid tijdens de eerste 1000 dagen van het leven numeriek te simuleren.
Doelstellingen op microniveau
De dynamiek en soortconcurrentie binnen de microbioomgemeenschappen (darm en mond) modelleren met behulp van input van in-vivo (WP2) en in-vitro studies (WP4) op functioneel en taxonomisch niveau.
Doelstellingen op mesoniveau
Het modelleren van de interactie tussen gastheer en microbioom in beide richtingen: hoe beïnvloedt het microbioom de gezondheid van de gastheer en vice versa.
Doelstellingen op macroniveau
De verbanden modelleren tussen verschillende parameters op macroniveau (leefstijl, voedingsgewoonten, demografie, socioculturele factoren) en de modellen op microniveau.
Actieve periode
Jaar 3-8
UvA-SILS, UvA-IBED, AUMC, TNO Microbiology & Systems Biology, TNO Child Health.


BaseClear, NIBI, Onkolyze, Supabase, Bètapartners.
Alle promovendi en postdocs in Werkpakket 3 (WP3) zijn inmiddels met hun onderzoek begonnen. Er worden regelmatig groepsbijeenkomsten van WP3 gehouden om de samenwerking binnen het werkpakket te bevorderen. De afgelopen maanden heeft WP3 de voltooiing van twee masterscripties en drie bachelorscripties begeleid.
Onderzoeksresultaten:
De masterscriptie van Allan Duah heeft geleid tot een artikel getiteld “FedDeepInsight – A privacy-first federated learning architecture for medical data”, dat is gepubliceerd in het tijdschrift Informatics in Medicine Unlocked.
Shivam Kumar (promovendus) en Xiaoqing Han (masterstudent) werken momenteel aan een onderzoeksartikel getiteld „Agent-Based Modeling of Microbial and Metabolite Interactions in Early Oral Biofilms”, dat zich momenteel in de laatste fase van voorbereiding bevindt.
Masterstudenten Zefan Zhu en Matthias Louws zijn co-auteurs van een manuscript getiteld “FAIR and Square: Implementing User-Centric Interfaces for a Secure and Compliant Healthcare Database”, dat wordt ingediend bij het tijdschrift *Information Systems Frontiers*. Het is ook beschikbaar als preprint: https://doi.org/10.21203/rs.3.rs-8205252/v1
Een artikel over edge-gebaseerde visualisaties van het microbioom, „Integrating Microbiome Data Visualization into FAIRDatabase using Edge Functions”, van van Eldijk, S. Kumar en M.V. Sheraton is gepubliceerd in het International Journal of Data Science and Analytics.
Een onderzoeksartikel van Tu-Ky Ly, getiteld „A PBK–Bayesian Network Framework for Gut Microbiome–Host Metabolic Modelling during the First 1000 Days of Life“, is geaccepteerd voor de ISCS 2026-conferentie en zal worden gepubliceerd in Lecture Notes in Computer Science.
Ontwikkeling van de infrastructuur:
Een server die nodig is voor de verwerking van gegevens uit metagenomische analyses wordt momenteel getest binnen de infrastructuur van de Universiteit van Amsterdam (UvA). Daarnaast zijn er parallel hieraan geautomatiseerde vertalingen van veldidentificatoren uit metagegevens uitgevoerd om de gegevensverwerking en -analyse te stroomlijnen.
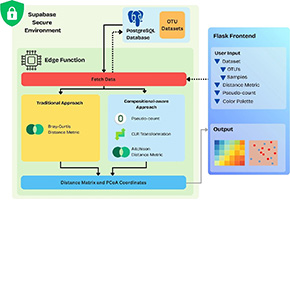
In een studie gepubliceerd in het International Journal of Data Science and Analytics introduceren onderzoekers Roman van Eldijk, Shivam Kumar en Vivek Sheraton M van WP3 een visualisatiemodule voor FAIRDatabase, een open-sourceplatform dat is ontworpen voor het verwerken van beschermde biologische gegevens. De tool pakt een kritieke bottleneck in de moderne wetenschap aan: de enorme hoeveelheid microbioomgegevens neemt explosief toe, maar wettelijke beperkingen en veiligheidsrisico’s dwingen wetenschappers vaak om maandenlang contracten door te spitten en bestanden te downloaden voordat ze zelfs maar aan hun analyse kunnen beginnen.
“Zie het als een streng beveiligde kluis waar je de inhoud kunt onderzoeken en complexe experimenten kunt uitvoeren, maar waarbij de gegevens zelf het gebouw nooit daadwerkelijk verlaten,” legt het team uit. Dit wordt bereikt door middel van edge computing, waarbij berekeningen worden uitgevoerd in beveiligde cloudomgevingen (met behulp van Supabase edge-functies) in plaats van op de lokale computer van een onderzoeker. Gevoelige genetische informatie blijft versleuteld en op zijn plaats, waardoor het risico op lekken of diefstal wordt geëlimineerd, terwijl geavanceerde analyse nog steeds mogelijk is. De innovatie draait niet alleen om beveiliging; het gaat erom die beveiliging naadloos te maken zonder in te boeten aan analytische kracht of wiskundige nauwkeurigheid. Voor de eindgebruiker, de wetenschapper, is de ervaring ontworpen om direct en intuïtief te zijn. De module genereert interactieve heatmaps en scatterplots (ook wel PCoA-plots genoemd) die bacteriële gemeenschappen in de visuele ruimte in kaart brengen. Onderzoekers kunnen gegevenspunten kleurgecodeerd weergeven op basis van patiëntmetadata, zoals leeftijd, dieet of ziektestatus, met behulp van paletten die specifiek zijn gekozen voor toegankelijkheid voor kleurenblinden.
Hoewel de tool is afgestemd op microbioomonderzoek, reiken de implicaties ervan veel verder dan darmbacteriën. Het dient als een proof-of-concept voor privacybeschermende visualisatie in elk vakgebied dat met gevoelige gegevens werkt, van menselijke genomica tot medische dossiers van patiënten. Door aan te tonen dat complexe, samenstellingsbewuste analyse kan samengaan met ijzersterke beveiliging, hebben de onderzoekers de basis gelegd voor een toekomst waarin wetenschappelijke ontdekkingen niet worden belemmerd door datasilo’s.
Lees meer
Ziekenhuizen en zorginstellingen beschikken over ongelooflijk waardevolle gegevens van patiënten en deelnemers aan onderzoek die tot belangrijke medische doorbraken kunnen leiden. Maar deze gegevens zijn privé en gevoelig, waardoor het veilig delen ervan een enorme uitdaging is onder strenge privacywetgeving. Om dit op te lossen, hebben Metahelath-onderzoekers Federated Learning (FL) onderzocht, een methode waarbij instellingen computationele/AI-modellen trainen op hun eigen privégegevens en alleen de verkregen inzichten (zoals bijgewerkte modelinstructies) met elkaar delen, nooit de ruwe patiëntendossiers.
Ze hebben een tool ontwikkeld met de naam ‘FedDeepInsight’ die complexe medische tabellen omzet in afbeeldingen (aangezien AI uitstekend is in het analyseren van afbeeldingen), waardoor het FL-proces nauwkeuriger wordt. Uit tests bleek dat door het toevoegen van differentiële privacy (zoals zorgvuldig gecontroleerde digitale ruis) geen individuele patiëntgegevens konden worden achterhaald uit de gedeelde informatie, waardoor een veelbelovende manier werd gecreëerd om de kracht van medische gegevens te ontsluiten en tegelijkertijd deze volledig veilig en privé te houden.

De auteurs hebben tools ontwikkeld voor het creëren van een grote, georganiseerde bibliotheek (database) voor microbioomgegevens (kiemen die in en op ons lichaam leven) die gemakkelijk toegankelijk en bruikbaar zijn voor onderzoekers. Dit zal wetenschappers helpen om informatie te delen en nieuwe manieren te bedenken om gezondheidsproblemen aan te pakken, terwijl ook de privacywetgeving wordt nageleefd en de persoonlijke informatie van mensen wordt beschermd. Ze gebruiken een speciaal platform om de database op te bouwen en een handige set tools te maken die zelfs niet-deskundigen kunnen gebruiken om de gegevens te begrijpen en ermee te werken. Hieronder volgt een technische samenvatting van het werk,
Het artikel stelt de creatie voor van een real-time FAIR (Findable, Accessible, Interoperable, Reusable) database voor de behandeling en opslag van menselijke microbiome en gastheer-geassocieerde gegevens. Deze databaseontwikkelingspijplijn heeft als doel innovatie te vergemakkelijken en kosten in onderzoek te verlagen door gestandaardiseerde, transparante en direct beschikbare (meta)data te maken.
De auteurs bespreken potentiële conflicten die voortkomen uit privacywetgeving en mogelijke sequenties van het menselijk genoom in metagenome shotgun gegevens en stellen alternatieve paden voor om in dergelijke gevallen naleving te bereiken. Ze identificeren gevoelige microbioomgegevens, zoals DNA-sequenties of geolokaliseerde metadata, en overwegen de rol van GDPR-gegevensregelgeving. De database is geïmplementeerd met behulp van een open-source ontwikkelplatform, Supabase, waarmee onderzoekers gegevens over het menselijk microbioom kunnen openen, uploaden, downloaden en er op een FAIR-conforme manier mee kunnen interageren. Daarnaast wordt een groot taalmodel (LLM) ingezet om kennisverspreiding en niet-expert gebruik van de database mogelijk te maken.
Lees meer

